Abstract
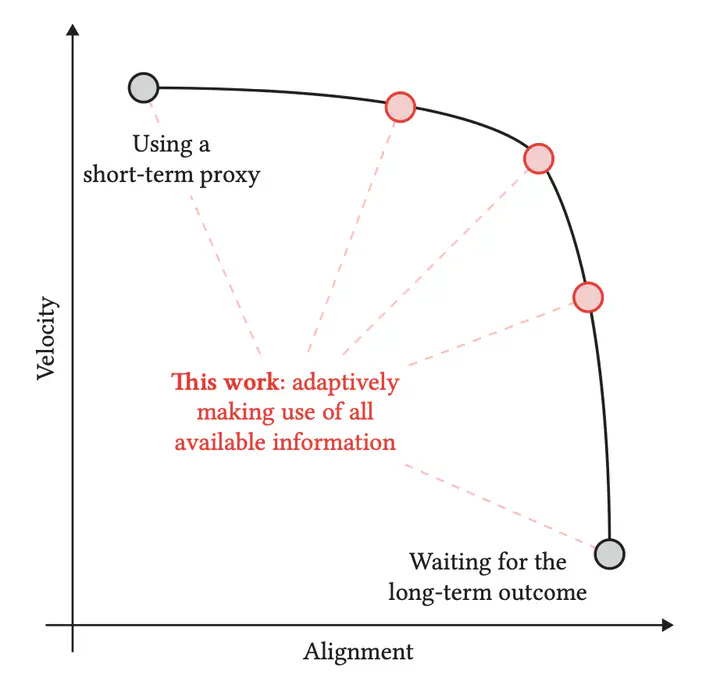
Recommender systems are a ubiquitous feature of online platforms. Increasingly, they are explicitly tasked with increasing users’ long-term satisfaction. In this context, we study a content exploration task, which we formalize as a multi-armed bandit problem with delayed rewards. We observe that there is an apparent trade-off in choosing the learning signal: Waiting for the full reward to become available might take several weeks, hurting the rate at which learning happens, whereas measuring short-term proxy rewards reflects the actual long-term goal only imperfectly. We address this challenge in two steps. First, we develop a predictive model of delayed rewards that incorporates all information obtained to date. Full observations as well as partial (short or medium-term) outcomes are combined through a Bayesian filter to obtain a probabilistic belief. Second, we devise a bandit algorithm that takes advantage of this new predictive model. The algorithm quickly learns to identify content aligned with long-term success by carefully balancing exploration and exploitation. We apply our approach to a podcast recommendation problem, where we seek to identify shows that users engage with repeatedly over two months. We empirically validate that our approach results in substantially better performance compared to approaches that either optimize for short-term proxies, or wait for the long-term outcome to be fully realized.
Thomas M. McDonald
PhD Student
I am a PhD student at The University of Manchester, currently working on physics-informed probabilistic deep learning.